
Showing posts with label pattern. Show all posts
Showing posts with label pattern. Show all posts
Monday, July 26, 2021

Sunday, July 25, 2021


Monday, May 31, 2021

Thursday, April 1, 2021
Row & Column Summary Commands "RowMeans()" & "ColMeans()" in R language over dataframe and Matrix objects

Special Row and Column Summary Commands
* Two summary commands used for row data are - rowMeans() and rowSums()
> rowMeans(mat01)
[1] 2.5 6.5 10.5 14.5
> rowSums(mat01)
[1] 10 26 42 58
* In the given example , each row in the dataframe has a
specific row name
* If the names of the rows along with the values for the various
rows would appear as a simple vector of values
> rowSums(mat01)
[1] 10 26 42 58
* The corresponding "colSums()" and
"colMeans()" commands function in the same manner .
* In the following example ... one can see the
"mean()" and "colMeans()" command with their comparison in
the following manner :
> colMeans(df)
[1] 7 8 9 10
> mean(mf)
[1] 8.5
* One can see that one would essentially get the same display /
result using the above two commands
* The commands use "na.rm" instruction which is used
by default and is set to FALSE
* If one wants to ensure that the "NA" items are removed from the dataframe then one can add "na.rm = TRUE " as an instruction in the command
Monday, March 15, 2021
Concept of Polymorphism in OOPS

Polymorphism
* The word "Polymorphism" comes from two Greek words
"Poly" meaning "many" and "morphos" meaning
"forms".
* Therefore , Polymorphism represents the ability to assume
several different forms
* In Programming , if an object or a method is
exhibiting different form of behaviours , then the object is
said to having polymorphic nature .
* Polymorphism provides flexibility in writing programs in such
a way that the programmer uses same method call to perform different operations
depending upon the requirement .
* Example Code for Polymorphism in Python :
- When a function can perform different tasks , then one can say
that the function is exhibiting polymorphism behaviour .
- A simple example to write a function :
def add(a,b):
print(a+b)
* Since in Python , the variables are not declared explicitly , we are passing two variables 'a' and 'b' to the add() function where the variables are added to each other .
* CASE 01 - While calling the function , if we pass two integers like 5 and 15 to the function , then the function displays 15 as output .
* CASE 02 - If we pass two strings , then the same function concatenates or joins those strings . This means that the same function is adding two integers or concatenating two strings .
* Since the Polymorphism function is performing two different tasks , it is said to exhibit polymorphism behaviour .
* One can consider the following example for the case of Polymorphism :
=================================================
# Function that exhibits Polymorphism
def add(a,b):
print(a+b)
# calling add() function and passing two integers
add(10,20)
# calling add() function and passing two strings
add("Core","Python"
* The Programming Languages which follow all the five features of OOPS – ( Classes with objects Abstraction , Encapsulation , Inheritance , Polymorphism) are called as object oriented programming languages .
* These type of behaviours are exhibited by C++ , Java and Python type of languages
Thursday, March 11, 2021

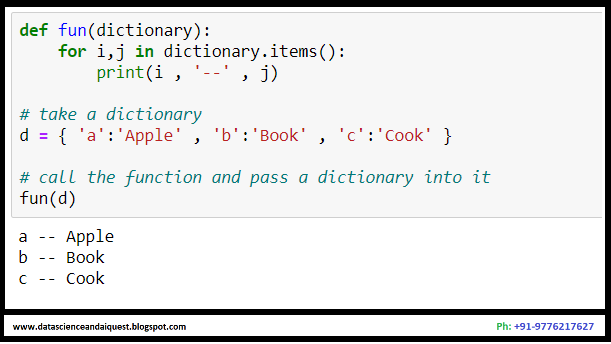
Friday, March 5, 2021
Keys and Values over Dictionary Objects in Python
Keys and Values over Dictionary Objects in Python

* Important points to remember while dealing with Dictionary
Objects in Python are the following :
1) One can use any type of datatype while dealing with any value
for a Dictionary Object in Python
2) A value can be a number , string , list , tuple or any other
dictionary object in Python
3) Keys in Python should obey the following rules
*** point-1 ***
Keys should be always unique . Duplicate Keys are not allowed in
Python . And If the user/programmer enters the same key again over the existing
dictionary , then the old key would be overwritten and only the new key would
be available . One can consider the following example for considering the case
of uniqueness of a Key in Python
emp =
{
'Data1':100,
'Data2':200,
'Data1':300
}
If someone wants to print the contents of the dictionary object
after the object has been created , then one would find that the values within
the dictionary for the data item which has been entered twice that is
"Data1" which is entered twice in the case would be printed only once
as a single data item can only exist once , and this data item would have the
higher value of the object .
print(emp)
Result :
{
'Data1':300,
'Data2':200
}
Here , one would be noticing that the values for the data item
are replaced with the one which has a higher value over the other data item
object which means that the dictionary object gives precedence to that sub-data
item within it to exist within it which has a higher value for the same /
duplicate key .
The screenshot for the above code is as given below :

*** point-2 ***
Keys should be immutable in nature . For example , one can use a
number , a string or a tuple as key since the keys are immutable in nature .
One cannot use lists or dictionaries as Keys . If as such , Keys are used then
one will get 'TypeError' . One can consider the following example in case of a
Dictionary Object :
emp =
{
[
'Data1']:100,
'Data2':200,
'Data1':300
}
# Here , upon compilation and execution of the code one would get to see that for the list element 'Data1' we get an error in the output section . This is because, as mentioned above, the key item should only be a number , string or a tuple in nature .
Wednesday, March 3, 2021
Cardinality Ratio concept in "Database and Management Systems" with explanatory figurative example
Cardinality Ratio concept in DBMS

Cardinality Ratio
It is the number of relationship instance that an
entity can participate in . If one tries to understand the relationship between
Student and Guide , then the relationship between the Student entity and the
guide entity can be described in the following entity - relationship diagram .

Considering the given case , one can observe and try to understand the given relationship with the help of a Entity Relation Diagram with the help of a Set Diagram .
Here , some scenarios emerge like the given case :
Case-1
One guide (G1) can guide two students (S1) and (S2)
whereas (S1) can only be guided by guide (G1) .

Case-2
Third Student (S3) can be guided by guide (G2) .

This is a kind of restriction set by the relationship where both the entity sets are mutually associated to each other by the relation between them . So here , the number of instance objects relation among each other is restricted and it can be also observed how the cardinality relationship is mapping one particular instance to another particular instance object through the given relationship diagram which depicts the way the entities can participate in .
From the above one can get a pretty good understanding of what a Cardinality Ratio is : -
Definition of Cardinality Ratio
The number of relationship instances that an entity
can participate in is called as the Cardinality Ratio .

From the above diagram it can be noted that , one
department would have only one HOD . So , in this case , the relationship would
be only 1 is to 1 .
From the diagram we deduce that :
Relationship R1 exists from Department D1 to HOD H1
.
Relationship R2 exists from Department D2 to HOD H2
.
Relationship R3 exists from the Department D3 to
HOD H3 .
A scenario over where such a type of relationship
exists where there is only one relationship mapping from one Set's instance
object to another Set's instance object is called a One to One relationship .
One can get a better understanding of this through
the help of a E-R diagram shown at the bottom of the above figure .
===================================================================
The second type of relationship that exists is called One to Many Relationship

In the given figure , one can notice that there is a relationship existing between many departments and one student . Each department will have multiple students and thus one can notice from the given relation diagram that multiple relations exist from one department to student of another set but the student would be associated with only one department .
This is an instance of Many to One Relationship which is depicted by the Ratio form of representation (1:M) .which is another form of cardinality ratio expressed in the form of Many to One relation .
This means that Many Instances of any particular Entity Type will be associated or will be participating in the "Has" relationship .
Many to Many Relationship
In the given example , if one can see then one
would be able to determine that there is Many to Many Relationship between the
students set and Subjects set .

This can be rightfully depicted in the form , Relation between a Student on the left hand side and Subject on the right hand side of the Relationship Diagram . One can notice that multiple instance objects belonging to the set "Student" bear a many to many relationship between students of the other entity set which is the "Subject" set .
The depiction of the relation has been done through the help of an E-R diagram .
===================================================================
Now , we can get to understand the behaviour of
these relationships that depict the manner in which relationships exist between
instance objects of one set with another or multiple other sets in the article's showcased manner
Friday, February 26, 2021
Keys of a Relational Database System ( detailed description with example on Primary Key Foreign Key , Candidate Key , Super Key )

·
One must have a way to
specify how the tuples within a given relational table are distinguished from
one another which is usually done with the help of attributes of the relation
which means that the attribute values of a tuple must be as such so that they
can uniquely identify any given tuple from a given database
·
In other words , no two tuples within a relation
are allowed to have exactly the same value for all the attributes within a
particular given relational table
·
So for the easier and
effective identification of any unique tuple or row from a database the concept
of recognition using "Superkey" was coined .
·
A Superkey is a
set of one or more attributes that when taken collectively allows the
identifier to uniquely identify a tuple within the relation .
·
Example :
"customer_id" attribute of the relation Customer is sufficient to distinguish one customer tuple from another tuple . Therefore , "customer_id" is a superkey in the relation .Similarly , the combination of the following attributes "customer_name" and "customer_id" is a superkey for the relation "customer" . The "customer_name" attribute of "customer" is not a superkey because several people might have the same name .
·
The concept of superkey is not sufficient
since a superkey may also contain extraneous attributes within it .
·
If one is often
interested in superkeys over a tuple for which no proper subset is a superkey
then such minimal superkeys are called as "candidate keys"
·
In such a scenario , several distinct sets of
attributes serve as a candidate key for a relation .Suppose a combination of "customer_name"
and "customer_street" is sufficient to distinguish among
members of the "customer" relation then both "customer_id"
and {"customer_name" , " customer_street"} are
called as "candidate keys"

·
Although the
attributes "customer_id" and "customer_name"
are together used to distinguish a "customer" tuple .. the
combination does not form a candidate key since the attribute "customer_id"
alone is a candidate key .
·
One can use the term
"Primary Key" to denote a candidate key which is chosen by a database
designer as the principal means of identifying the tuples within a Relation
· A key ( whether primary , candidate or super) is a property of the entire relation rather than the individual tuples of the relation . Any two individual tuples in the relation are prohibited from having the same value upon the KEY attribute at any point of time . The designation of a Key represents a constraint in the real world enterprise being modelled .
·
Candidate Keys must be chosen with utmost care
. As noted , the name of person for being selected as a form of candidate Key
is not completely sufficient since a situation may arise from the given
scenario where multiple people with the same initials might happen and in such
a case , all the data might be fetched with the same initials at any given
point of time within the database . And as such duplicacy of value for such a
candidate key is not entertained and as such any two tuples within the relation
are prohibited from having the same value on the key attribute at the same
point of time . The designation of a Key represents a constraint in the real
world enterprise being modelled .
·
The Primary Key should be chosen in such a
manner that its attribute values are never or rarely changed . For example ,
the address field of a person should not be part of the primary key , since the
value is likely to change with the shifting of base / home from time to time .
In the similar order , Social Security numbers of the dweller of any place can
never change and remains the same from the time of birth to the time of death
of the citizen . In the similar manner , Unique Identifiers generated by
enterprises against any transaction are not likely to change and remain
constant throughout and the given field could be considered as a primary key
for a transaction relation .
·
Therefore , formally
reiterating once again , if R could be considered as a Relation Schema and one
would say that a subset K of R is a superkey for the table then the
framer of the relational table restricts consideration to relations r(R) in
which no two distinct tuples have the same values on all the attributes in K .
This means that if tuple t1 and tuple t2 are in relation r and t1 != t2 then
t1[K] != t2[K] .
·
A relation schema , say r1 may include among
its attributes the primary key of another relation schema say r2 where this
attribute is called as a foreign Key from relation r1 referencing the relation
r2 . Here , the relation r2 is also called as the "referencing
relation" of the the Foreign Key dependency and "r2" is
called as the referenced relation of the foreign Key .
· For example , the attribute branch_name in Account schema or relation is a foreign key . For example , the attribute "branch_name" in Account schema is a foreign key from Account schema referencing Branch schema since branch_name is the primary key of Branch Schema . In any database instance , given any tuple say "tn" from the "Account" relation there must be some tuple say "tn" from the "Account" relation there must be some tuple say "t2" in the branch relation such that the value of the branch_name attribute of tn is the same as the value of the primary key that is "branch_name" of tb


· Therefore , it is customary to list the primary key attributes of a relation schema before other attributes for example , the attribute branch_name of Branch Schema is listed first since it is the primary key
·
A database schema along with primary key and
foreign key dependencies can be depicted pictorially as per the below given
schema diagram . In the figure , a schema diagram for the banking enterprise
has been depicted . Here , each relation appears as a Box with its attributes
listed inside them and the name of the relation written above them . Hence , if
there are primary key attributes , then a horizontal line crosses the box with
the primary key attributes listed above the line in grey . Foreign key
dependencies appear in the form of arrows from the foreign key attributes of
the referencing relation to the primary key of the referenced relation .
Many database systems provide design tools with a graphical user interface for the
creation of schema diagrams .
Subscribe to:
Posts (Atom)

-
Write a program in Python to calculate the factorial value of a number When we talk about factorial of a number , then the factorial of tha...

