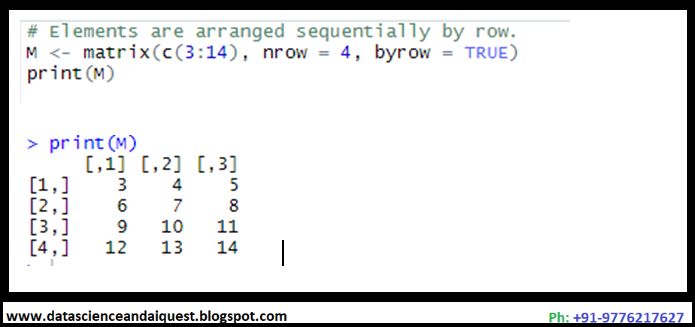
Union Operation - RDBMS
Fundamental Relational Algebra Concept
=======================================
* Scenario where a Union Operation over a rdbms table could be
used : -
Consider a query to find the names of all the bank customers who
have either an account or a loan or both in a bank .
* To find the names of the customer who have an account and also
a deposit account in the bank , the search query would consider the search to
take over "depositor" relation table and the "borrower" relation
table .
* In order to find out the names of all the customers with a
loan in the bank , the query that could be used for the operation would be :
{figure-01}
The upper relational equation is a form of projection which
allows us to produce the relevant relation that returns the argument relation
specified within the parenthesis . So as we are interested in finding out the names
of the customers who have a loan account , the
relevant result would be fetched from the projection relation as
mentioned in the above statement .
* Similarly , if we want to know the names of all the customers
with an account in the bank , then it can be expressed in the following
projection equation :
{figure-02}
* Therefore , in order to find the answer to the raised question in our scenario that is discussed in the opening
statement , one needs to do a "Union" operation over the two sets
which is : we need all the customer names that appear in either both or two of
the relations which can be found out by using the binary operation Union upon
both the queries . The relevant relational equation can be represented in the given
manner :
{figure-03}
* The resulting relation for the query would result in a relation
with the relevant tuples from both the tables
* The resulting relations are sets from which duplicate values
are eliminated .
In Hindsight :
In our example , we took the union of two sets , both of which
consisted of the attribute "customer_names" values . In general , one
must ensure that unions are taken between compatible relations which would generate
the appropriate results without duplicates.
* Points to note when using a Union Operation over relational
sets :
If r is a set
and s is set , and one needs to find { r U s } , If r is a set and s is set ,
and one needs to find { r U s } , then the conditions that should satisfy and
hold for both relations
1)
The relations r and s must
be of the same type and they must have the same number of attributes
2) The domains of the ith attribute of r and ith attribute of s must be the same for all values of i . One may
note that , both r and s are either database relations or temporary relations
that are the result of relational algebra expressions as given in figure 1 and figure
2 of the article .